
A 6-minute read on what the latest MeasuringU research tells us about AI in usability analysis — and ideas on how to actually fix it.
Here's the scenario most AI companies & AI-first research teams are banking on:
AI watches the usability test video
--> AI flags the problems
--> Researcher reviews and ships the report
--> Everyone saves time, does more research, proves more value.
It’s a win-win for everyone. Clean. Efficient. Scalable.
Right?.... Riiiiiiight.
Here's what the data actually says.
The Study
The fantastic and venerable team at MeasuringU — James R. Lewis, Jeff Sauro, Will Schiavone, and Lucas Plabst, PhD — ran a somewhat rigorous experiment to examine the efficacy of using AI to conduct a usability analysis of a participant video. In their two-part blog posts (part 1, part 2), they shone a very harsh spotlight on AI’s ability to correctly identify usability problems compared to a human researcher.
But before we get into the nitty gritty details, let’s set the scene first.
The study setup: four professional UX researchers and two LLMs (ChatGPT-5.4 Thinking and Gemini 3 Flash Thinking) each independently reviewed the same six-minute usability test video, analyzing the on-screen behavior of a participant conducting a task-based usability test.
The Task: book a sushi restaurant in Denver on OpenTable. Straightforward. Real session. No tricks.
Human-identified problems were the gold standard.
AI found roughly half of what humans found (see Figure 1 below) — which, honestly, is a promising starting point. But AI also generated 11 additional problems that no human flagged.
So the team went back and classified and compared the problems AI "found" against the trained human researchers to see which were true, false alarms (plausible, but inferred), and which were a case of the hallulus.
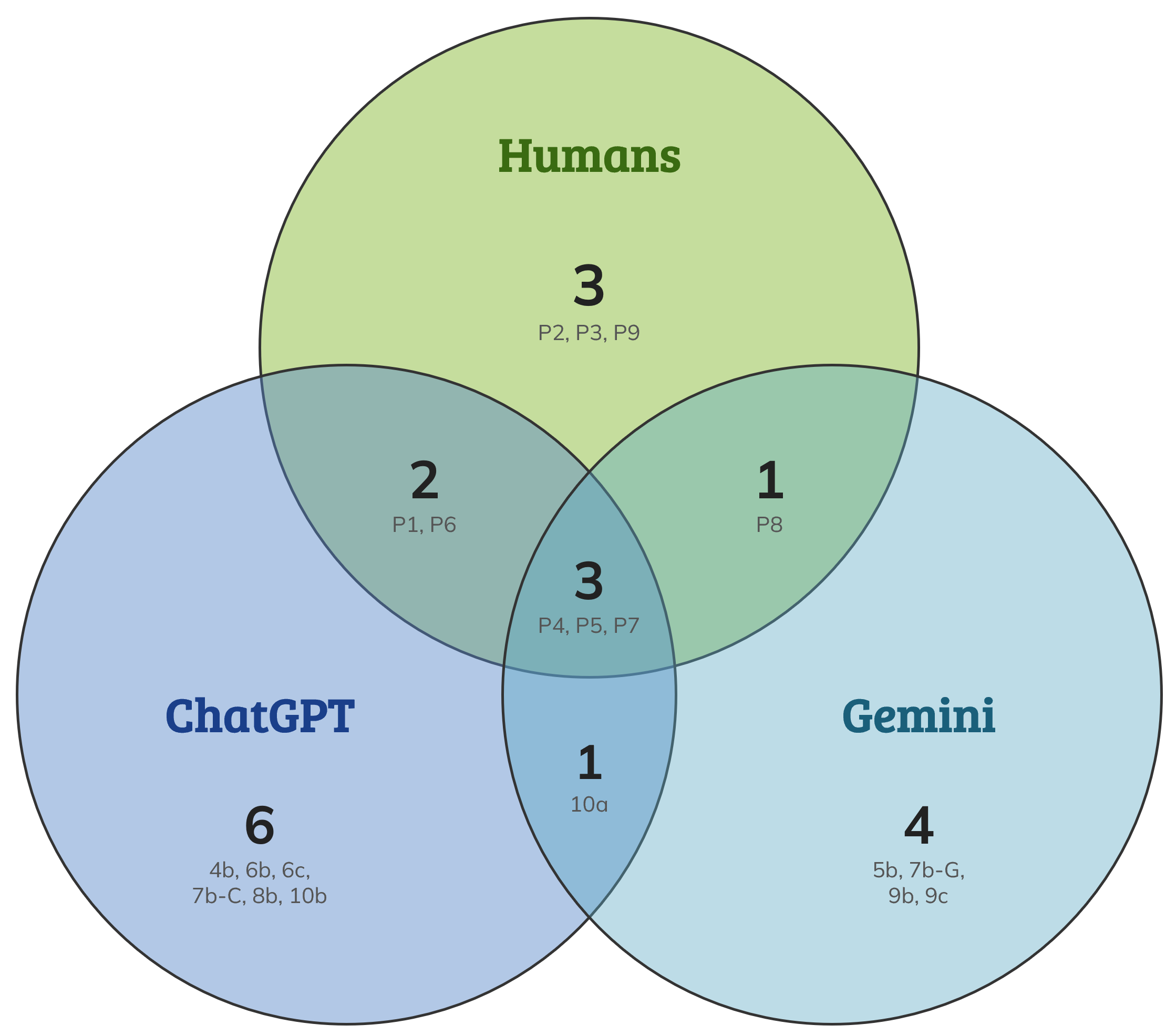
Figure 1: Venn diagram of usability problem discovery by humans, ChatGPT, and Gemini. Source: Lewis, J. R., Sauro, J., Schiavone, W., & Plabst, L. (2026, May 5). Can AI detect usability problems like researchers? MeasuringU. https://measuringu.com/ai-vs-human-usability-problem-analysis-of-a-video/
What They Found
Of those 11 AI-only problems:
7 were false alarms — real observations, misread as problems
3 were hallucinations — things that simply never happened in the video
1 was a genuine find — a real problem every human researcher missed
That's 10 out of 11 requiring human cleanup....not great.
The false alarms are frustrating but manageable. ChatGPT fixated on the seafood/sushi labeling issue and spiraled, generating five variations of the same misinterpretation across multiple runs. Annoying, but at least the observations were grounded in something real.
The hallucinations are more problematic.
AI confidently reported things that never happened. Wrong price tier selected. Wrong reservation time. Task failure when the task was actually completed. All delivered with the same authority as the legitimate findings.
Here's what should give every AI-first research team pause: you can't identify the hallucinations without going back to the video yourself. There's no shortcut. Human review is never optional — it’s still part of the job.
Questions I'd Want Answered
First off [enter slow clap here], MeasuringU documented more of their setup than most AI studies do. The full prompt is published. The runs used paid pro subscriptions of both tools, at default settings, with the video dragged directly into the consumer chat interfaces. And the think-aloud audio was in the video — the AIs clearly processed it, because Gemini quoted the participant's verbal comments, with timestamps, in its narratives.
That still leaves open questions that matter for how practitioners interpret and apply these findings.
What does the model actually do with a dragged-in video? This is the biggest unknown, and it isn't MeasuringU's omission — the consumer interfaces simply don't document it. Frame sampling rate, audio transcription, resolution: each shapes what AI can observe, misinterpret, or fabricate. And the audio detail cuts deep. Gemini could quote what the participant said at 05:13 and still hallucinate what she did. That should make the hallucinations more unsettling, not less.
Which exact builds, on which dates? The versions are named and were held constant within the study. But consumer models update continuously, and minor version changes can meaningfully shift behavior. Without run dates and specific versions, replication is a guess.
What's in the vendors' system prompts? Consumer interfaces wrap every conversation in hidden system prompts and safety filtering that change without notice. Enterprise teams working through the API can't directly reproduce consumer-interface results, and vice versa. Which environment you test in is a variable, even when you can't see inside it.
Was AI given a definition of "usability problem"? The published prompt asks the AI to "look for problems the participant has" with a few examples — but no formal definition of what counts. Neither AI asked for one. Each model operated on its own interpretation, which may or may not match the standard used by the human researchers. If you can't control for it in a study, you can at least state it.
These aren't gotchas. They're the questions a rigorous researcher should ask of any study — including ones we find compelling. MeasuringU is doing genuinely important work here. More methodological transparency would make it even more powerful and actionable for the field.
My Take
Regardless of these methodological questions. There's still some interesting takeaways for me:
The one genuine AI find was actually good. Celebrate progress, where progress is due. Gemini caught a participant using Ctrl-F to search a cuisine filter because "sushi" wasn't surfacing — something none of the four human researchers noticed. Real problem. Real insight. That matters.
But you had to wade through 10 others to get there. (Not cool, AI. Not cool.) AI didn't eliminate the analytical work. It just shifted it. While it's not necessarily a bad trade, it's definitely an annoying one—especially when the whole premise and promise is for it to be more efficient and, at the very least, accurate.
When the Baymard Institute tested ChatGPT-4's ability to audit webpage screenshots in 2023, the model's suggestions had an 80% false-positive rate and a 20% accuracy rate (Holst, 2023).
In March 2025, Microsoft researchers tested three AI tools on their ability to accurately conduct heuristic evaluations — a different method from video analysis, but addressing the same underlying question. False-positive rates ranged from 25–50%, and the tools discovered only 11–37% of the violations that human reviewers verified (Ianni & Hillman, 2025).
There's a tradeoff buried in their data worth remembering, too: when one tool's algorithm was tuned to surface more issues, its false-positive rate climbed with it. Coverage and accuracy pulled against each other. That's real improvement over 2023 — and still nowhere near trustworthy.
Baymard cofounder Christian Holst's framing is the one to remember:
“..a tool that’s right 70% of the time sounds acceptable until you realize you can’t tell which recommendations are the wrong ones ”
While 70% accuracy is tempting, a 30% error rate is a wild goose chase with potentially costly consequences.
So there’s potential, but realizing that potential and mitigating any problems are a pain.
Perhaps there’s a way to minimize that pain…
How to Minimize the Pain
The study is a diagnosis—not a prognosis. Luckily, the technology and stack have advanced. And while there isn’t a cure for AI’s hallucination problem, there are ways—prompt engineering, context engineering, and best practices—that can help our AI patient progress.
1. Mandate timestamps via structured outputs. Don't just ask AI to flag problems — give it a structured template that requires a timestamp for every single finding. No timestamp, no problem makes the cut. This one constraint would have caught all three hallucinations immediately: none of them could produce verifiable evidence from the video. It also creates an auditability trail, so human reviewers know exactly where to look and can verify claims in seconds rather than scrubbing through an entire session.
2. Apply Chain of Verification (CoVe). After AI generates its findings, have it run a second pass — independently verifying each claim against the source material before it surfaces to a human. "Did this actually happen? At what timestamp? What's the direct evidence?" CoVe is a systematic verification process, not just a confidence check. It forces AI to interrogate its own outputs rather than report them unchallenged — and it catches a meaningful percentage of hallucinations before they ever reach your review queue.
3. Provide explicit usability definitions in your prompt (or as a reference file). AI doesn't inherently know what distinguishes a usability problem from a design preference, a false alarm, or a task failure. As Baymard outlined in their approach, curating defined context lead to a 95% accuracy rate (Moran, 2026). The key is giving it a working definition upfront — including what a false positive looks like in the context of your research. A shared definitional framework calibrates what AI looks for and how it classifies what it finds. This is also a direct answer to one of the methodological gaps above: if you can't control for it in the study, control for it in your workflow.
4. Ask AI to rate its own confidence. Have it score each flagged problem from one to ten and explain why. Use that score to triage where human attention goes first. It doesn't eliminate review — but it makes the wading directional instead of random, which matters when you're trying to scale without sacrificing accuracy.
5. Use adversarial agents or prompting. Run a second agent whose explicit job is to challenge the first one's findings. "Attack this problem list. What's unverifiable? What's misclassified? What never happened?" Red-teaming your AI analysis before it reaches a human reviewer catches a meaningful percentage of errors that a single-pass approach will always miss. This is applied methodology, not a theoretical fix — and it's one of the more powerful levers available to teams already working with multi-agent workflows.
6. Treat this study as training data for its own eval. This is the one I keep coming back to. MeasuringU has inadvertently built something rare: a labeled ground-truth dataset—video, human-verified problems, and AI outputs classified by type. That's the exact structure needed to fine-tune a usability-specific model, benchmark future AI tools against a known standard, or build an eval harness that systematically catches hallucination-prone behavior before it ships. Someone should run with this. MeasuringU team — you’re likely sitting on a gold mine of training data. Open source please ;-)
The Bigger Picture
While these might mitigate the problems, none of them fully solves the problem. General-purpose LLMs weren't trained on usability data and heuristics. They're pattern-matching on language — not watching and interpreting human behavior the way a trained researcher does. Prompt engineering has a ceiling.
However, context engineering might get you closer. Worth being clear-eyed: Baymard's self-reported 95% accuracy rate came from engineering, not prompting — probabilistic AI restricted to pattern recognition, with all evaluative judgment running through deterministic, research-backed rules (Moran, 2026). You won't replicate that with a better prompt. But between structured outputs, CoVe, adversarial prompting, and better definitional context, you can close the gap — and make human review faster, more targeted, and a lot less painful.
The field keeps asking: does AI replace human researchers in usability analysis?
Based on this data — not close….at least not yet.
So at least in this case, AI didn't make the work disappear. It just moved it.
In this era of AI, our job — as researchers and as a field — is to ensure that it doesn’t mearly move the work, but actually minimizes the drudgery.
Am I saying that we should scrap and discredit AI as a potential partner for conducting usability analysis? No, far from it.
Let's Talk About It
The potential for AI as an amplifier is real. However, until we take the time to define standards and intentionally build workflows and systems to meet our expectations, it will remain overshadowed by the guise of AI-slop.
Most teams haven’t slowed down to learn and build with intention and integrity. Yet.
This is exactly the kind of research the AIxUXR community was built to dig into together.
If you're running your own experiments with AI in usability analysis — what's working, what's failing, what you'd add to this conversation — I want to hear from you. Connect with me on LinkedIn and let's figure this out collectively.
And if you haven't read the full MeasuringU series (part 1, part 2) yet, do it.
Worth 👏 every 👏 minute 👏.
Credits & Resources
Holst, C. (2023, October 18). Testing ChatGPT-4 for 'UX audits' shows an 80% error rate & 14–26% discoverability rate. Baymard Institute. https://baymard.com/blog/gpt-ux-audit
Ianni, J., & Hillman, S. (2025, March 10). Why AI tools are not ready to replace human heuristic evaluations — yet. UXR @ Microsoft, Medium. https://medium.com/uxr-microsoft/why-ai-tools-are-not-ready-to-replace-human-heuristic-evaluations-yet-e56a143c0967
Lewis, J. R., Sauro, J., Schiavone, W., & Plabst, L. (2026, April 28). How reliable is AI at finding UI problems? MeasuringU. https://measuringu.com/ai-usability-problem-analysis-of-a-video/
Moran, K. (2026, January 30). Demand accuracy in your AI tools: Lessons from Baymard Institute. Nielsen Norman Group. https://www.nngroup.com/articles/baymard-ai-tool-accuracy/
Lewis, J. R., Sauro, J., Schiavone, W., & Plabst, L. (2026, May 5). Can AI detect usability problems like researchers? MeasuringU. https://measuringu.com/ai-vs-human-usability-problem-analysis-of-a-video/
Lewis, J. R., Sauro, J., Schiavone, W., & Plabst, L. (2026, May 26). Does AI find real UI problems or just hallucinations? MeasuringU. https://measuringu.com/does-ai-find-real-ui-problems-or-just-hallucinations/
Sankaran, A. (2025, December 18). The hallucination tax: Generative AI's accuracy problem. Forbes Business Council. https://www.forbes.com/councils/forbesbusinesscouncil/2025/12/18/the-hallucination-tax-generative-ais-accuracy-problem/